Haoru Xue*, Xiaoyu Huang*, Dantong Niu*, Qiayuan Liao*, Thomas Kragerud, Jan Tommy Gravdahl, Xue Bin Peng, Guanya Shi, Trevor Darrell, Koushil Sreenath, Shankar Sastry
University of California Berkeley, Carnegie Mellon University, Simon Fraser University
2025
Camera Inputs + “Sit on [chair / box / table]” = 👇
Visual Navigations: “Walk to / pass XXX”
More WBC Tasks Coming Soon (Kinematics Dataset Preview) 👇
Vision–language–action (VLA) models have demonstrated strong semantic understanding and zero-shot generalization, yet most existing systems assume an accurate low-level controller with hand-crafted action “vocabulary” such as end-effector pose or root velocity. This assumption confines prior work to quasi-static tasks and precludes the agile, whole-body behaviors required by humanoid whole-body control (WBC) tasks. To capture this gap in the literature, we start by introducing the first sim-to-real-ready, vision-language, closed-loop benchmark for humanoid WBC, comprising over 150 tasks from 10 categories. We then propose LeVERB: Latent Vision-Language-Encoded Robot Behavior, a hierarchical latent instruction-following framework for humanoid vision-language WBC, the first of its kind. At the top level, a vision-language policy learns a latent action vocabulary from synthetically rendered kinematic demonstrations; at the low level, a reinforcement-learned WBC policy consumes these latent verbs to generate dynamics-level commands. In our benchmark, can zero-shot attain a 80% success rate on simple visual navigation tasks, and 58.5% success rate overall, outperforming naive hierarchical whole-body VLA implementation by 7.8 times.


LeVERB uses a System 1 – System 2 architecture with a “latent vocabulary” as the interface:
- LeVERB-VL: a 102.6 M transformer-based vision-language backbone that converts language instruction and vision context into a latent verb.
- LeVERB-A: a 1.1 M transformer-based whole-body action expert that decodes a latent verb into dynamics-level humanoid action outputs.
This sounds too small?
LeVERB is a first-of-its-kind whole-body VLA for humanoids, trained on only 154 rendered trajectories, augmented with visual randomization. Larger models like Pi0 can easily overfit on this small-scale dataset.
We want to provide the first proof-of-concept in this area, and encourage future work on open-world generalization.
0
Rendered Frames
0
Total Hours
0
Rendered Episodes
∞
Possibilities
What cannot be measured cannot be managed. We first create LeVERB-Bench, a photorealistic, whole-body vision-language benchmark for humanoid robots. Data is obtained by dropping retargeted human motion capture data into IsaacSim, and render with diverse visual context.
- A benchmark: closed-loop, dynamically accurate, evaluation tool in IsaacSim for whole-body vision-language humanoid policies.
- A dataset: pre-rendered selection of the benchmark tasks.
Simulation enables infinite visual feature scaling. We randomize over millions of combinations in camera angles, assets and materials.
We further augment the 17.1 hours of rendered trajectories with 2.7 hours of text-only trajectory to boost diversity.
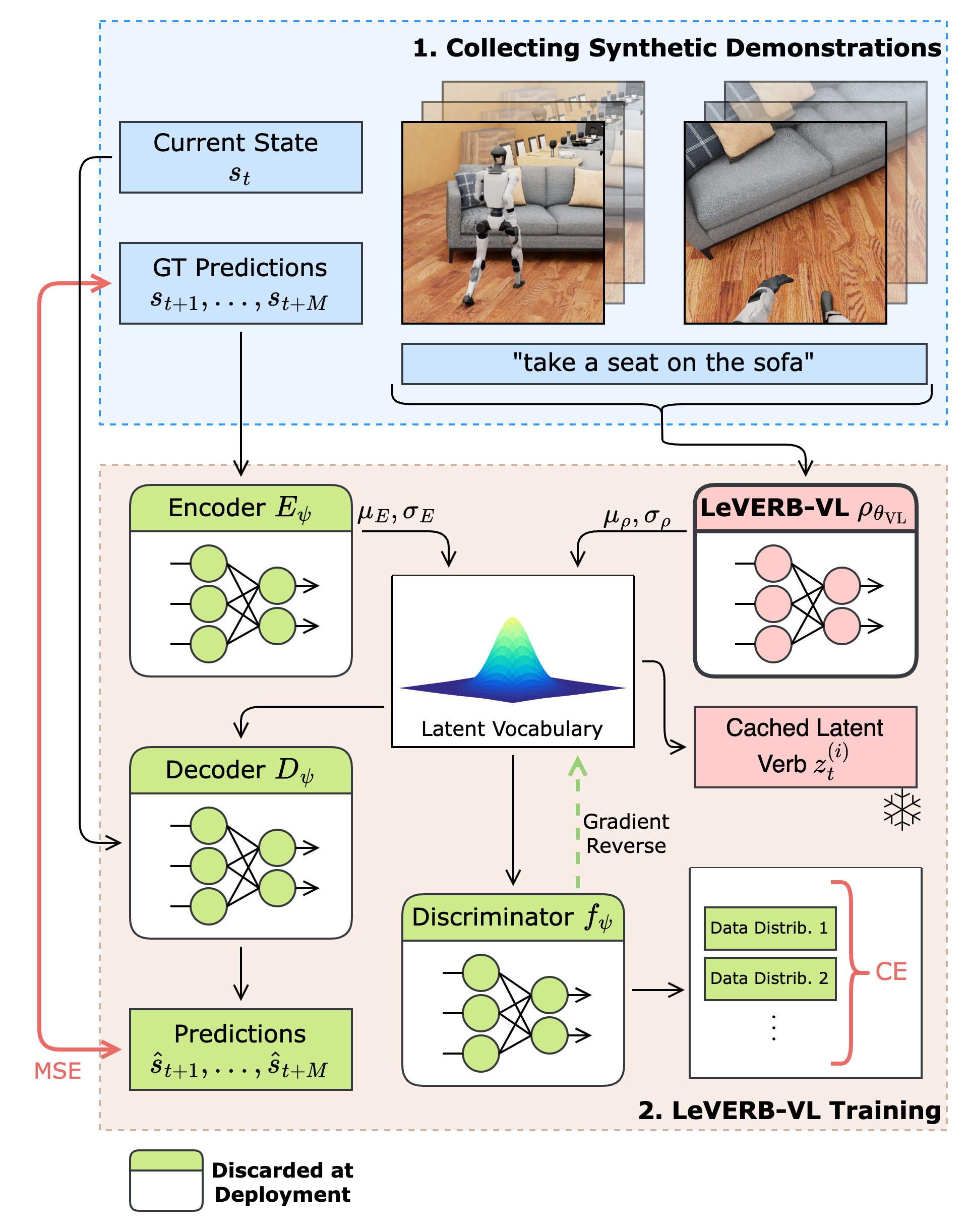
- Representing whole-body skill in a latent space is naturally expressive and interpolatable.
- Inspired by physics-based animation works such as PULSE and MaskedMimic, we train LeVERB-VL with a kinematic trajectory reconstruction task using a C-VAE formulation.
- LeVERB-VL learns to output a latent vocabulary prior that aids the trajectory decoder‘s reconstruction.
- A privileged encoder assists LeVERB-VL, but a special loss formulation suppresses its output (see MaskedMimic)
- A discriminator makes sure the distribution of visual data and text-only augmentation data blends into the same latent vocabulary distribution by trying to classify the two data sources based on the latent information. See NeuralFly.
- Trained latent verbs for each episode are cached to condition LeVERB-A’s training.
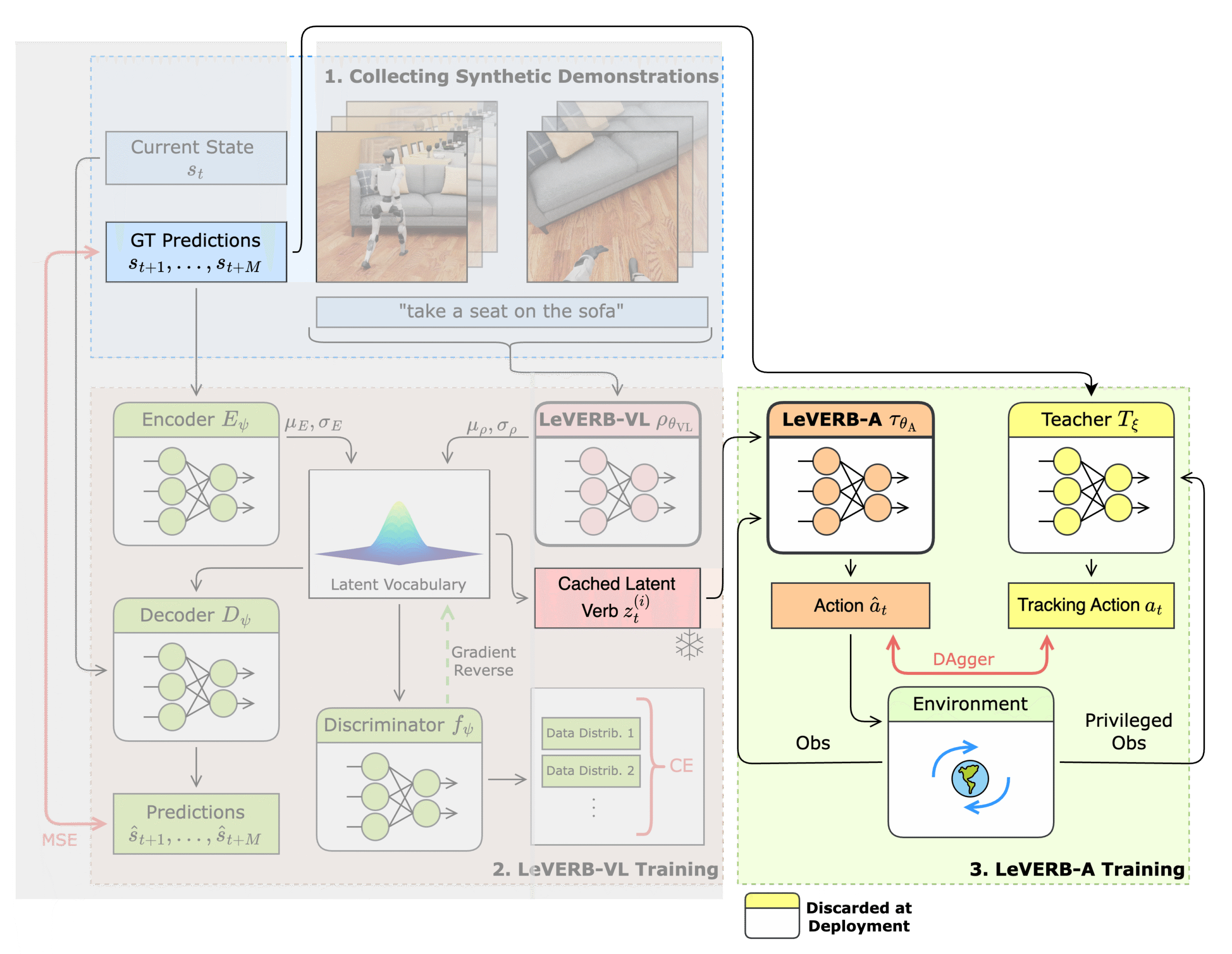
- We first train a teacher tracking policy that can track the kinematic states in all the episodes.
- We then DAgger-distill it onto a student policy (LeVERB-A), who only conditions on the latent verb.
- End goal: LeVERB-A is aligned with LeVERB-VL’s latent vocabulary.
(See Full Metrics and Ablations in Paper)
| LeVERB | No-Discriminator | No-Encoder | Vanilla VLA | |
| VNF – Simple | 80 | 75 | 75 | 0 |
| VNF – Intermediate | 75 | 55 | 60 | 0 |
| VNF – Hard | 50 | 5 | 25 | 0 |
| VN & Sitting | 5 | 0 | 5 | 0 |
| Language-Only | 97 | 58 | 97 | 25 |
| Overall | 58.5 | 33 | 53 | 7.5 |
- Vanilla VLA: removing the C-VAE sampling procedure.